TentangAI.com – Belajar AI bagi pelajar bukan sekadar menghafal kode. Memahami data adalah langkah fundamental dan harus menjadi tahap pertama dalam setiap proyek machine learning. Program sekolah menengah yang memungkinkan siswa membangun sesuatu yang orisinal cenderung memberikan pemahaman yang lebih tahan lama dibandingkan format yang hanya berbasis pelajaran saja.
Kesalahan fatal yang sering dilakukan pemula adalah menganggap model sebagai bintang utama, padahal Shardul More menekankan bahwa datanya adalah kuncinya melalui pernyataannya: “I thought the model was the star of the show. It’s not—the data is.” (Artinya: Saya pikir model adalah bintang utamanya. Ternyata bukan—datanya adalah kuncinya). Fokus yang salah pada algoritma tanpa memahami kualitas input data akan menghambat perkembangan kemampuan teknis dalam jangka panjang.
Roadmap Belajar AI Berdasarkan Jenjang Pendidikan
Roadmap belajar AI dibedakan menjadi tiga: tingkat SMP fokus pada konsep dasar dan penggunaan alat no-code; tingkat SMA mulai mempelajari Python, matematika dasar (matriks/turunan), dan framework seperti scikit-learn; sedangkan tingkat Mahasiswa mendalami deep learning menggunakan PyTorch atau TensorFlow serta riset arsitektur neural networks.
Banyak pelajar terjebak dalam pola belajar yang tidak efisien karena langsung melompat ke arsitektur kompleks tanpa dasar yang kuat. Sebuah studi dari AI/ML SIGCSE ’22 menunjukkan bahwa pelajar sering mengalami kesulitan saat harus merangkai komponen-komponen independen proyek machine learning menjadi satu kesatuan yang kohesif.
Fase SMP: Eksplorasi Konsep Tanpa Coding
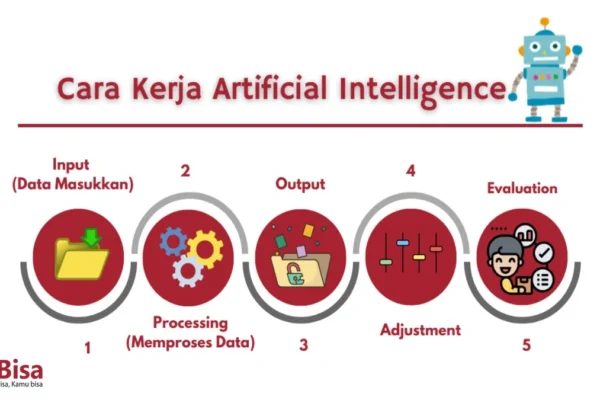
Pada jenjang ini, pelajar sebaiknya tidak dipaksa menulis baris kode yang rumit. Fokus utama adalah memahami logika bagaimana mesin belajar melalui alat bantu visual atau platform no-code. Tujuannya agar mereka memahami konsep input, proses, dan output secara intuitif.
Fase SMA: Fondasi Python dan Matematika
Memasuki tingkat SMA, kurikulum mandiri harus mulai menyentuh bahasa pemrograman Python dan matematika pendukung. Pelajar perlu memahami konsep matriks dan turunan untuk mengerti cara kerja optimasi algoritma. Pengenalan library machine learning seperti scikit-learn (sklearn) menjadi langkah krusial di fase ini.
Fase Mahasiswa: Deep Learning dan Spesialisasi
Mahasiswa harus mulai bergerak menuju spesialisasi yang lebih teknis. Penggunaan framework tingkat lanjut seperti PyTorch atau TensorFlow menjadi standar industri. Pada tahap ini, pemahaman mengenai arsitektur neural networks yang lebih dalam sangat diperlukan untuk melakukan riset atau membangun aplikasi berbasis kecerdasan buatan yang kompleks.
Solusi Low-Spec: Belajar AI Tanpa Laptop Mahal
Keterbatasan perangkat keras sering kali menjadi penghambat utama bagi pelajar yang ingin mendalami kecerdasan buatan. Namun, kebutuhan akan GPU kelas atas dengan harga mencapai ribuan dolar tidak harus menjadi syarat mutlak untuk memulai langkah pertama.
Pelajar dapat memanfaatkan layanan berbasis cloud yang menyediakan akses gratis ke komputasi awan. Dengan menggunakan platform seperti Google Colab atau Kaggle, Anda dapat menjalankan kode Python yang berat tanpa membebani prosesor laptop pribadi. Framework populer seperti Keras, TensorFlow, dan PyTorch dapat dijalankan sepenuhnya di lingkungan browser tersebut.
Shortcut: Gunakan Google Colab untuk mengakses GPU gratis secara instan guna mempercepat proses training model tanpa perlu instalasi lokal yang rumit.
Menguasai Fondasi: Mengapa Data Lebih Penting dari Model
Proyek machine learning yang sukses dimulai dengan Exploratory Data Analysis (EDA). Teknik ini melibatkan penggunaan statistik ringkasan dan visualisasi untuk memahami distribusi serta outlier sebelum membangun model apa pun.
Membangun model canggih di atas data yang berantakan hanya akan menghasilkan output yang menyesatkan. Oleh karena itu, penguasaan terhadap teknik pembersihan dan eksplorasi data menjadi keterampilan yang jauh lebih berharga daripada sekadar menghafal sintaks library.
Teknik EDA untuk Pemula
Untuk melakukan eksplorasi data secara efektif, pelajar wajib menguasai tiga library utama dalam ekosistem Python: pandas, seaborn, dan matplotlib. Berikut adalah langkah-langkah praktis dalam melakukan EDA:
- Gunakan fungsi
df.describe()pada library pandas untuk menampilkan statistik ringkasan seperti mean, median, dan standar deviasi secara cepat. - Lakukan seleksi fitur numerik menggunakan perintah
df.select_dtypes(include=['int64', 'float64'])untuk mempermudah proses visualisasi distribusi. - Gunakan matplotlib atau seaborn untuk membuat histogram dan count plots guna mendeteksi adanya outlier atau ketidakseimbangan data.
Pentingnya Feature Engineering
Setelah data dipahami, langkah berikutnya adalah Feature Engineering. Proses ini mencakup pembuatan fitur baru yang lebih representatif, seperti menghitung rasio dari fitur yang ada atau menggunakan PolynomialFeatures untuk menangkap hubungan non-linear antar variabel.
Menghindari Jebakan Error dan Kegagalan Proyek
Kegagalan dalam proyek AI sering kali bukan disebabkan oleh kesalahan logika pemrograman, melainkan kesalahan metodologi dalam penanganan data dan evaluasi model.
Pelajar harus mewaspadai beberapa kesalahan teknis berikut:
- Data Leakage: Terjadi saat informasi dari test set secara tidak sengaja masuk ke dalam training set. Hal ini menyebabkan model tampak memiliki akurasi sangat tinggi saat pengembangan, namun gagal total saat diuji dengan data dunia nyata.
- Overfitting: Kondisi di mana model terlalu kompleks sehingga hanya menghafal data latihan dan gagal melakukan generalisasi pada data baru.
- Model Bias: Terjadi ketika data pelatihan tidak memiliki keberagaman yang cukup, misalnya kekurangan representasi kelompok usia atau gender tertentu, sehingga keputusan AI menjadi tidak adil.
Kurasi Sumber Belajar dan Framework Populer
Gunakan referensi dari para ahli berikut untuk mempercepat proses belajar Anda melalui literatur yang sudah teruji.
| Nama Tokoh | Fokus Keahlian | Konteks Materi |
|---|---|---|
| Michael Nielsen | Neural Networks | Buku dasar Deep Learning |
| Daniel Bourke | PyTorch | Kursus praktis Machine Learning |
| Mehreen Saeed | RNNs | Matematika di balik Recurrent Neural Networks |
| Krishnendu Chaudhury | Deep Learning | Arsitektur dan matematika mendalam |
| Anshuman Mishra | Neural Architectures | Struktur arsitektur jaringan saraf |
Selain membaca buku, pelajar disarankan untuk mengikuti tutorial praktis yang berdurasi singkat namun padat. Sebagai contoh, terdapat tutorial PyTorch blitz yang dapat diselesaikan dalam waktu sekitar 60 menit untuk memberikan gambaran cepat tentang cara kerja framework tersebut.
Bagi mereka yang ingin mendalami arsitektur yang lebih modern, terdapat kursus singkat mengenai model Transformer yang biasanya memakan waktu sekitar 12 hari untuk dipelajari secara komprehensif.
| Arsitektur | Karakteristik Data | Kegunaan Utama |
|---|---|---|
| Feedforward Neural Networks | Data independen (tidak berurutan) | Klasifikasi gambar atau data tabular standar |
| Recurrent Neural Networks (RNNs) | Data berurutan (time series/teks) | Pemrosesan bahasa alami dan prediksi deret waktu |
Perbedaan mendasar terletak pada ketergantungan data. Feedforward dirancang untuk titik data yang bersifat independen, sementara RNN memiliki mekanisme “memori” untuk menangani data berurutan atau time series.
FAQ
Apa perbedaan utama antara Feedforward dan RNN?
Feedforward digunakan untuk memproses data yang bersifat independen satu sama lain, di mana input saat ini tidak dipengaruhi oleh input sebelumnya. Sebaliknya, RNN dirancang untuk menangani data berurutan atau time series karena memiliki kemampuan untuk menyimpan informasi dari langkah sebelumnya sebagai memori.
Bagaimana cara menghindari overfitting pada model AI?
Untuk mencegah overfitting, pelajar dapat menggunakan teknik K-fold Cross-validation guna memastikan performa model konsisten di berbagai subset data. Selain itu, pastikan kompleksitas model tidak melebihi kapasitas dataset yang tersedia agar model tidak sekadar menghafal noise dalam data.
Apa itu Data Leakage dan mengapa berbahaya?
Data leakage terjadi ketika informasi dari test set secara tidak sengaja masuk ke dalam proses training. Hal ini berbahaya karena menciptakan ilusi performa yang sangat tinggi selama pengembangan, namun model akan gagal saat diimplementasikan di lingkungan produksi karena telah “mengintip” jawaban.